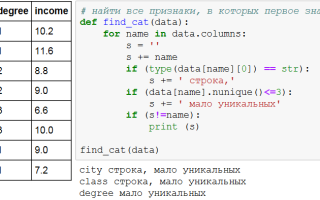
В современном мире анализа данных объединение различных источников информации становится ключевым этапом в обработке и интерпретации данных. В этой статье мы рассмотрим, как эффективно объединять кадры данных в Python с помощью библиотеки Pandas, которая предоставляет мощные инструменты для работы с табличными данными. Вы узнаете о различных методах объединения, таких как слияние и конкатенация, а также о том, как правильно обрабатывать данные для получения наиболее точных и информативных результатов. Эта статья будет полезна как новичкам, так и опытным пользователям, стремящимся улучшить свои навыки работы с данными и оптимизировать процессы анализа.
Работа с основами
Работа с основами в Pandas начинается с создания кадров данных, которые представляют собой двумерные структуры данных, подобные таблицам. Кадры данных могут быть созданы из различных источников, включая списки, словари и другие структуры данных.
Создайте кадры данных в Python
Для создания кадра данных в Python с использованием библиотеки Pandas, сначала необходимо импортировать библиотеку. Это можно сделать с помощью следующей команды:
import pandas as pd
После этого вы можете создать кадр данных из словаря, где ключи будут именами столбцов, а значения — списками, представляющими данные. Например:
data = {
'Имя': ['Алексей', 'Мария', 'Иван'],
'Возраст': [25, 30, 22],
'Город': ['Москва', 'Санкт-Петербург', 'Екатеринбург']
}
df = pd.DataFrame(data)
print(df)
Этот код создаст следующий кадр данных:
Имя Возраст Город
0 Алексей 25 Москва
1 Мария 30 Санкт-Петербург
2 Иван 22 Екатеринбург
Преобразуйте свои словари в фреймы данных
Если у вас есть данные в формате словаря, вы можете легко преобразовать их в кадр данных. Например, если у вас есть несколько словарей, каждый из которых представляет собой запись, вы можете создать кадр данных следующим образом:
data = [
{'Имя': 'Алексей', 'Возраст': 25, 'Город': 'Москва'},
{'Имя': 'Мария', 'Возраст': 30, 'Город': 'Санкт-Петербург'},
{'Имя': 'Иван', 'Возраст': 22, 'Город': 'Екатеринбург'}
]
df = pd.DataFrame(data)
print(df)
Результат будет аналогичен предыдущему примеру. Это позволяет легко организовать и структурировать данные, что делает их более удобными для анализа.
Кроме того, вы можете использовать методы Pandas для преобразования существующих данных в кадры данных. Например, если у вас есть список списков, вы можете создать кадр данных, указав имена столбцов:

data = [
['Алексей', 25, 'Москва'],
['Мария', 30, 'Санкт-Петербург'],
['Иван', 22, 'Екатеринбург']
]
df = pd.DataFrame(data, columns=['Имя', 'Возраст', 'Город'])
print(df)
Таким образом, вы можете легко создавать кадры данных из различных источников и форматов, что является основой для дальнейшего анализа и обработки данных в Python с использованием Pandas.
Эксперты в области анализа данных подчеркивают важность объединения кадров данных для эффективной обработки и анализа информации. В Python существует несколько мощных инструментов, таких как библиотека Pandas, которая позволяет легко и быстро объединять различные наборы данных. Специалисты рекомендуют использовать функции merge и concat, которые обеспечивают гибкость в работе с данными. Например, merge позволяет объединять данные по общим столбцам, что особенно полезно при работе с реляционными базами данных. Кроме того, использование concat помогает объединить данные по вертикали или горизонтали, что упрощает процесс подготовки данных для анализа. Эксперты также отмечают, что правильное объединение данных способствует более глубокому пониманию информации и позволяет извлекать ценные инсайты, что в свою очередь повышает качество принимаемых решений.
https://youtube.com/watch?v=lsCBbWOOEI8
Создайте кадры данных в Python
В качестве первого шага импортируйте библиотеку Pandas в файл Python. Pandas — это сторонняя библиотека, которая обрабатывает DataFrames в Python. Вы можете использовать оператор импорта для использования библиотеки следующим образом:
import pandas as pd
Вы можете назначить псевдоним имени библиотеки, чтобы сократить ссылки на код.
Вам нужно создать словари, которые вы можете конвертировать в DataFrames. Для достижения наилучших результатов создайте две переменные словаря — dict1 и dict2 — для хранения определенных фрагментов информации:
dict1 = {"user_id": ["001", "002", "003", "004", "005"],
"FName": ["John", "Brad", "Ron", "Roald", "Chris"],
"LName": ["Harley", "Cohen", "Dahl", "Harrington", "Kerr-Hislop"]}
dict2 = {"user_id": ["001", "002", "003", "004"], "Age": [15, 28, 34, 24]}
Помните, что вам нужно иметь общий элемент в обоих значениях словаря, чтобы он служил первичным ключом для последующего объединения ваших фреймов данных.
| Метод объединения | Описание | Преимущества/Недостатки |
|---|---|---|
pd.concat() |
Объединяет несколько DataFrame по оси (по строкам или столбцам). | Гибкий, позволяет объединять DataFrame с разными индексами. Может привести к дубликатам индексов, если не указать ignore_index=True. |
pd.merge() |
Объединяет DataFrame на основе общих столбцов (ключей). | Эффективен для объединения данных по связанным столбцам. Различные типы объединения (внутреннее, левое, правое, полное). Может быть сложным для больших наборов данных с неявными ключами. |
pd.join() |
Объединяет DataFrame на основе индексов. | Простой для объединения по индексам. Менее гибкий, чем pd.merge(). |
Интересные факты
Вот несколько интересных фактов о том, как объединять кадры данных в Python:
-
Пандас и SQL: Библиотека Pandas в Python предоставляет функции, аналогичные SQL-запросам, такие как
merge(),join()иconcat(). Это позволяет пользователям, знакомым с SQL, легко адаптироваться к манипуляциям с данными в Pandas, так как они могут использовать знакомые концепции для объединения данных из разных источников. -
Объединение по ключам: При объединении DataFrame в Pandas можно использовать один или несколько ключей, что позволяет создавать сложные структуры данных. Например, можно объединить таблицы по нескольким столбцам, что дает возможность более точно сопоставлять записи и избегать дублирования данных.
-
Разные типы объединения: Pandas поддерживает различные типы объединения данных, такие как «inner», «outer», «left» и «right». Это позволяет пользователям выбирать, какие данные сохранять в результате объединения. Например, «outer» объединение сохранит все записи из обоих DataFrame, заполняя отсутствующие значения NaN, что может быть полезно для анализа неполных данных.
Эти факты подчеркивают мощные возможности библиотеки Pandas для работы с данными и их объединения в Python.

Преобразуйте свои словари в фреймы данных
Преобразование словарей в фреймы данных является простым и эффективным способом начать работу с данными в Pandas. Словари в Python представляют собой структуры данных, состоящие из пар «ключ-значение», что делает их удобными для хранения и организации информации. Pandas предоставляет функцию DataFrame, которая позволяет легко преобразовать словари в фреймы данных.
Для начала, создадим простой словарь. Например, пусть у нас есть словарь, содержащий информацию о студентах и их оценках:
data = {
'Имя': ['Алексей', 'Мария', 'Дмитрий'],
'Возраст': [21, 22, 20],
'Оценка': [85, 90, 78]
}Теперь мы можем использовать этот словарь для создания фрейма данных. Для этого мы просто передаем наш словарь в функцию pd.DataFrame():
import pandas as pd
df = pd.DataFrame(data)
print(df)
После выполнения этого кода мы получим следующий вывод:
Имя Возраст Оценка
0 Алексей 21 85
1 Мария 22 90
2 Дмитрий 20 78
Как видно, каждый ключ словаря стал заголовком столбца, а значения — строками в соответствующих столбцах. Это позволяет нам легко манипулировать данными, используя мощные инструменты, предоставляемые Pandas.
Кроме того, можно создавать фреймы данных из вложенных словарей. Например, если у нас есть словарь, где ключи — это имена студентов, а значения — еще один словарь с их возрастом и оценками, мы можем сделать следующее:
data = {
'Алексей': {'Возраст': 21, 'Оценка': 85},
'Мария': {'Возраст': 22, 'Оценка': 90},
'Дмитрий': {'Возраст': 20, 'Оценка': 78}
}
Для преобразования этого словаря в фрейм данных мы можем использовать параметр orient='index':
df = pd.DataFrame.from_dict(data, orient='index')
print(df)
Результат будет аналогичен предыдущему примеру, но теперь имена студентов будут в качестве индексов:
Возраст Оценка
Алексей 21 85
Мария 22 90
Дмитрий 20 78
Таким образом, преобразование словарей в фреймы данных в Pandas — это простой и удобный способ организации информации, который позволяет легко выполнять дальнейшие операции анализа и обработки данных.
Объединение кадров с помощью функции слияния
Функция слияния — это первая функция Python, которую вы можете использовать для объединения двух фреймов данных. Эта функция принимает следующие аргументы по умолчанию:
pd.merge(DataFrame1, DataFrame2, how= type of merge)
Где:
- pd — это псевдоним библиотеки Pandas.
- merge — это функция, которая объединяет DataFrames.
- DataFrame1 и DataFrame2 — это два кадра данных для слияния.
- как определяет тип слияния.
Доступны некоторые дополнительные необязательные аргументы, которые можно использовать при наличии сложной структуры данных.
Вы можете использовать разные значения параметра «как», чтобы определить тип выполняемого слияния. Эти типы слияния будут знакомы, если вы использовали SQL для объединения таблиц базы данных.
Слияние слева
Слияние слева, или left join, представляет собой один из наиболее распространенных способов объединения двух кадров данных. При выполнении этого типа слияния все строки из левого кадра данных сохраняются, а строки из правого кадра данных добавляются только в том случае, если существует совпадение по ключевому столбцу. Если совпадений нет, то в результирующем кадре данных будут заполнены значения NaN для столбцов правого кадра.
Для начала, давайте создадим два кадра данных, которые мы будем использовать для демонстрации слияния слева. Предположим, у нас есть кадр данных с информацией о сотрудниках и другой кадр с информацией о зарплатах.
import pandas as pd
Кадр данных с информацией о сотрудниках
employees = pd.DataFrame({
'EmployeeID': [1, 2, 3, 4],
'Name': ['Alice', 'Bob', 'Charlie', 'David']
})
Кадр данных с информацией о зарплатах
salaries = pd.DataFrame({
'EmployeeID': [1, 2, 4],
'Salary': [70000, 80000, 75000]
})
Теперь, когда у нас есть два кадра данных, мы можем выполнить слияние слева, используя метод merge() из библиотеки Pandas. В этом методе мы указываем, что хотим объединить данные по столбцу EmployeeID, который является общим для обоих кадров.
merged_data = pd.merge(employees, salaries, on='EmployeeID', how='left')
print(merged_data)
Результат выполнения этого кода будет выглядеть следующим образом:
EmployeeID Name Salary
0 1 Alice 70000.0
1 2 Bob NaN
2 3 Charlie NaN
3 4 David 75000.0
Как видно из результата, все сотрудники из левого кадра данных (employees) присутствуют в итоговом кадре. Для сотрудников с ID 2 и 3, у которых нет соответствующих записей в кадре зарплат, значения в столбце Salary заполнены NaN. Это позволяет легко идентифицировать, какие сотрудники не имеют информации о зарплате.
Слияние слева полезно в ситуациях, когда необходимо сохранить все записи из одного источника данных, даже если для некоторых из них отсутствуют соответствующие данные в другом источнике. Это особенно актуально в анализе данных, когда важно не потерять информацию о всех объектах, которые мы изучаем.

Правое слияние
Правильный тип слияния сохраняет значения второго кадра данных без изменений и извлекает соответствующие значения из первого кадра данных.
Внутреннее слияние
Внутреннее слияние — это один из наиболее распространенных способов объединения кадров данных, который позволяет получить только те строки, которые имеют совпадения в обоих объединяемых фреймах. Это означает, что результатом внутреннего слияния будут только те записи, которые присутствуют в обоих исходных наборах данных.
Для выполнения внутреннего слияния в Pandas используется метод merge(). Этот метод принимает несколько параметров, которые позволяют настроить процесс слияния в соответствии с вашими потребностями. Основные параметры включают left, right, how, on, left_on, и right_on.
Рассмотрим пример. Предположим, у нас есть два кадра данных: один с информацией о клиентах, а другой с их заказами.
import pandas as pd
Создаем первый кадр данных с клиентами
clients = pd.DataFrame({
'client_id': [1, 2, 3, 4],
'client_name': ['Alice', 'Bob', 'Charlie', 'David']
})
Создаем второй кадр данных с заказами
orders = pd.DataFrame({
'order_id': [101, 102, 103, 104],
'client_id': [1, 2, 2, 5],
'amount': [250, 150, 200, 300]
})
Выполняем внутреннее слияние
merged_data = pd.merge(clients, orders, on='client_id', how='inner')
print(merged_data)
В этом примере мы объединили два кадра данных по столбцу client_id. Параметр how='inner' указывает, что мы хотим выполнить внутреннее слияние. В результате мы получим новый кадр данных, который будет содержать только тех клиентов, у которых есть заказы.
Вывод будет следующим:
client_id client_name order_id amount
0 1 Alice 101 250
1 2 Bob 102 150
2 2 Bob 103 200
Как видно из результата, в итоговом кадре данных содержатся только записи клиентов, которые сделали заказы. Клиент с client_id равным 3 и клиент с client_id равным 4 не попали в итоговый набор, так как у них нет соответствующих записей в кадре данных с заказами.
Внутреннее слияние — это мощный инструмент для фильтрации данных, позволяющий сосредоточиться только на тех записях, которые имеют значение для вашего анализа. Используя этот метод, вы можете легко объединять данные из различных источников, сохраняя только наиболее релевантную информацию.
Внешнее слияние
Внешний тип слияния сохраняет все совпадающие и несовпадающие значения и объединяет кадры данных вместе.
Как использовать функцию Concat
Функция concat в библиотеке Pandas позволяет объединять несколько фреймов данных вдоль определенной оси. Это особенно полезно, когда у вас есть данные, которые необходимо объединить по строкам или столбцам. Давайте рассмотрим, как использовать эту функцию на практике.
Первым делом, чтобы использовать concat, вам нужно импортировать библиотеку Pandas и создать несколько фреймов данных. Например:
import pandas as pd
data1 = {'A': [1, 2], 'B': [3, 4]}
data2 = {'A': [5, 6], 'B': [7, 8]}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
Теперь у нас есть два фрейма данных df1 и df2. Чтобы объединить их, мы можем использовать функцию pd.concat(). По умолчанию concat объединяет фреймы по строкам (оси 0). Вот как это выглядит:
result = pd.concat([df1, df2])
print(result)
Результат будет следующим:
A B
0 1 3
1 2 4
0 5 7
1 6 8
Обратите внимание, что индексы в объединенном фрейме данных не были сброшены. Если вы хотите сбросить индексы и получить последовательные номера, вы можете использовать параметр ignore_index=True:
result = pd.concat([df1, df2], ignore_index=True)
print(result)
Теперь результат будет выглядеть так:
A B
0 1 3
1 2 4
2 5 7
3 6 8
Если вам нужно объединить фреймы по столбцам (оси 1), вы можете указать параметр axis=1:
result = pd.concat([df1, df2], axis=1)
print(result)
Результат будет следующим:
A B A B
0 1 3 5 7
1 2 4 6 8
Функция concat также позволяет добавлять дополнительные параметры, такие как join, который определяет, как обрабатывать индексы, которые не совпадают. По умолчанию используется outer, что означает, что будут включены все индексы. Если вы хотите оставить только те индексы, которые присутствуют в обоих фреймах, вы можете установить join='inner'.
Таким образом, функция concat является мощным инструментом для объединения фреймов данных в Pandas, позволяя вам легко и гибко обрабатывать ваши данные.
Слияние фреймов данных с Python
DataFrames являются неотъемлемой частью Python, учитывая их гибкость и функциональность. Учитывая их многогранное использование, вы можете использовать их широко для выполнения различных задач с максимальной легкостью.
Если вы все еще изучаете Python DataFrames, попробуйте импортировать несколько файлов Excel, а затем комбинируйте их с помощью различных подходов.
Объединение по ключевым столбцам
Объединение данных по ключевым столбцам является одной из самых распространенных операций в анализе данных. В Python для этой цели чаще всего используется библиотека Pandas, которая предоставляет мощные инструменты для работы с табличными данными. В этой части статьи мы подробно рассмотрим, как объединять кадры данных с помощью различных методов, таких как merge, join и concat.
Для начала, давайте создадим два примера датафреймов, которые мы будем использовать для демонстрации объединения:
import pandas as pd
# Создаем первый датафрейм
df1 = pd.DataFrame({
'id': [1, 2, 3],
'name': ['Alice', 'Bob', 'Charlie']
})
# Создаем второй датафрейм
df2 = pd.DataFrame({
'id': [1, 2, 4],
'age': [25, 30, 22]
})
Теперь у нас есть два датафрейма: df1 содержит информацию о пользователях, а df2 — информацию об их возрасте. Мы можем объединить эти два датафрейма по столбцу id, который является ключевым столбцом для обоих наборов данных.
Метод merge
Метод merge позволяет объединять два датафрейма по одному или нескольким ключевым столбцам. По умолчанию он выполняет внутреннее объединение (inner join), что означает, что в результирующий датафрейм будут включены только те строки, которые имеют совпадающие значения в ключевых столбцах.
result = pd.merge(df1, df2, on='id')
print(result)
Результат будет следующим:
id name age
0 1 Alice 25
1 2 Bob 30
Как видно, в результирующем датафрейме остались только строки с id 1 и 2, так как только они присутствуют в обоих исходных датафреймах.
Типы объединений
Метод merge также позволяет выполнять различные типы объединений, такие как:
- inner: возвращает только строки с совпадающими ключами (по умолчанию);
- outer: возвращает все строки из обоих датафреймов, заполняя отсутствующие значения
NaN; - left: возвращает все строки из левого датафрейма и совпадающие строки из правого;
- right: возвращает все строки из правого датафрейма и совпадающие строки из левого.
Например, если мы хотим выполнить внешнее объединение, мы можем сделать это следующим образом:
result_outer = pd.merge(df1, df2, on='id', how='outer')
print(result_outer)
Результат будет следующим:
id name age
0 1 Alice 25.0
1 2 Bob 30.0
2 3 Charlie NaN
3 4 NaN 22.0
Теперь мы видим, что строки с id 3 и 4 также включены в результат, и отсутствующие значения заполнены NaN.
Метод join
Метод join позволяет объединять датафреймы по индексу. Этот метод удобен, когда нужно объединить несколько датафреймов, используя их индексы в качестве ключей. Например:
df1.set_index('id', inplace=True)
df2.set_index('id', inplace=True)
result_join = df1.join(df2, how='inner')
print(result_join)
Результат будет аналогичен результату, полученному с помощью метода merge:
name age
id
1 Alice 25
2 Bob 30
Метод concat
Метод concat используется для объединения датафреймов по оси (по строкам или столбцам). Он не требует наличия ключевых столбцов и может быть полезен, когда нужно объединить несколько датафреймов в один. Например:
df3 = pd.DataFrame({
'id': [5, 6],
'name': ['David', 'Eve']
})
result_concat = pd.concat([df1.reset_index(), df3], ignore_index=True)
print(result_concat)
Результат будет следующим:
id name
0 1 Alice
1 2 Bob
2 3 Charlie
3 5 David
4 6 Eve
Таким образом, мы рассмотрели основные методы объединения датафреймов в Python с использованием библиотеки Pandas. Каждый из этих методов имеет свои особенности и может быть использован в зависимости от конкретной задачи анализа данных. Понимание того, как правильно объединять данные, является ключевым навыком для эффективной работы с данными в Python.
Вопрос-ответ
Как объединить два фрейма данных в Python pandas?
Использование функции concat Pandas предоставляет функцию concat для объединения DataFrames. Функция concat принимает последовательность DataFrames в качестве входных данных и объединяет их вдоль указанной оси. По умолчанию она объединяет DataFrames вертикально (вдоль строк).
Как объединить два фрейма данных в Python?
Для объединения этих DataFrames pandas предоставляет несколько функций, таких как concat(), merge() , join() и т. Д . В этом разделе вы попрактикуетесь в использовании функции merge() pandas. Вы можете заметить, что DataFrames теперь объединены в один DataFrame на основе общих значений, присутствующих в столбце id обоих DataFrames.
Как объединить элементы в списке Python?
В Python для объединения строк часто используются метод . Join() и оператор +. Метод . Join() – это строковый метод, который применяется для объединения элементов итерируемого объекта (например, списка или кортежа) в одну строку.
Как объединить функции в Python?
Основные методы конкатенации – «+» и join. Чтобы использовать «+», нужно просто поместить слева и справа от него строки для объединения. Для того, чтобы использовать join, нужно вызвать его у строки, и в качестве аргумента подать итерируемый объект, содержащий строки.
Советы
СОВЕТ №1
Используйте библиотеку Pandas для объединения данных. Она предоставляет удобные функции, такие как `merge()`, `concat()` и `join()`, которые позволяют легко объединять DataFrame по различным критериям, таким как общие столбцы или индексы.
СОВЕТ №2
Перед объединением данных убедитесь, что столбцы, по которым вы будете выполнять слияние, имеют одинаковые названия и типы данных. Это поможет избежать ошибок и упростит процесс объединения.
СОВЕТ №3
Используйте параметр `how` в функции `merge()` для выбора типа объединения: `inner`, `outer`, `left` или `right`. Это позволит вам контролировать, какие данные будут включены в итоговый DataFrame и как будут обрабатываться отсутствующие значения.
СОВЕТ №4
Не забывайте проверять результат объединения с помощью методов, таких как `head()` и `info()`, чтобы убедиться, что данные были объединены корректно и все необходимые столбцы присутствуют в итоговом наборе данных.